AI Training Made More Efficient with Spintronic Hardware: A Probabilistic Gradient of Activation Function Backpropagation Algorithm (p-GAF-BP)
Date:22-05-2026 Print
Artificial intelligence has penetrated into daily life and work, powering a wide range of applications from image recognition, voice interaction and task scheduling to autonomous driving, intelligent robots, scientific research and artistic creation. Deep neural networks support such numerous intelligent applications and act as a core driving force for technological revolution and industrial upgrading; a fundamental enabling algorithm is the error Back-propagation (BP) algorithm. The algorithm is essentially a perfect marriage of artificial deep neural network architecture and the gradient descent algorithm, which endows neural networks with autonomous learning ability through reverse error transmission and iterative weight updating. Originating in optimal control theory in the 1960s and formalized in the 1970s, BP was systematically improved and popularized in 1986 by Professor Hinton, a Nobel Prize laureate in physics, successfully solving the problem of training deep networks and becoming the cornerstone of deep learning. However, as model scales grow, AI training is facing increasingly severe bottlenecks in computing power and energy consumption. Public data shows that a single training run of some large-scale language models can consume millions of kilowatt-hours, comparable to the annual electricity consumption of hundreds of households. High energy consumption constrains model scaling, increases deployment costs, and restricts use on many edge devices. Therefore, achieving more efficient and energy-saving training without reducing model performance has become a pain point and bottleneck restricting the development of the artificial intelligence field.
Why Traditional BP Is Energy-Intensive
The core process of the BP algorithm includes signal forward propagation and error backward propagation, and the entire operation process can be decomposed into four basic operations: multiplication, addition, nonlinear function activation and derivation of activation functions, among which a large number of multiplication operations are the main cause of computing intensity and high energy consumption. Current mainstream AI hardware acceleration schemes, such as Graphics Processing Units (GPUs) and compute-in-memory chips based on Resistive Random-Access Memory (RRAM) arrays, mainly speed up operations by improving the parallelism of multiply-accumulate operations, but they do not fundamentally reduce the demand for computations, especially multiplications. In neural networks, a large number of neurons operate in the saturation region of the activation function, where their gradients approach zero, so they contribute little to the decline of training error and thus to weight updates, yet they still participate in complete gradient calculations, resulting in significant computing power waste. The research team from the Institute of Physics, Chinese Academy of Sciences proposes that reasonable approximation or unbiased estimation of activation function gradients, together with dynamic elimination of invalid nodes and related operations without changing the network structure, is an effective strategy to improve the efficiency of the BP algorithm.
Breakthrough: p-GAF-BP Algorithm Powered by Spintronic Hardware
The team proposed a brand-new optimization idea: using the intrinsic physical randomness of Spin-Orbit Torque Magnetic Tunnel Junctions (SOT-MTJ), realizing the probabilistic approximation of activation function gradients through SOT-MTJ hardware random sampling, and constructing a more efficient probabilistic Gradient of Activation Function Backpropagation (p-GAF-BP) algorithm. The SOT-MTJ is composed of a heavy metal layer W that generates spin current, a CoFeB/MgO/CoFeB Magnetic Tunnel Junction (MTJ) and other functional layers. The antiparallel/parallel magnetic states of the two CoFeB magnetic layers in the MTJ can make the MTJ present high/low resistance states, which can be used to encode 1/0 digital information. The heavy metal W can generate pure spin current via charge-to-spin conversion, thereby switching the magnetization of the bottom CoFeB layer. In the past, SOT-MTJ was mainly used for the R&D of high-performance Magnetoresistive Random-Access Memory (MRAM). In a new approach, the team noticed that SOT-MTJ also has continuously adjustable random switching characteristics — the probability of switching from a low-resistance state to a high-resistance state is continuously modulated by an external current, so it can be used as a true random number generator with adjustable probability. The probability distribution of its high and low resistance states is highly consistent with typical activation functions such as sigmoid σ. The probability of observing a "1, 0" pair in two consecutive independent samplings is thus highly matched with the derivative of the above sigmoid activation function σ'=σ(1-σ). With this feature, the team transformed the originally complex and precise activation function derivation operation into two simple 0/1 random sampling operations for SOT-MTJ. When the sampling result is a "1, 0" pair, it means that the network node works in the non-saturation region with a high probability, so its gradient is retained; otherwise, its gradient is directly set to zero, and subsequent operations related to it can be reduced. This method can realize dynamic pruning of gradient operations without modifying the network topology, automatically retain effective updates of high-sensitivity nodes and skip invalid operations of saturation region nodes, thus greatly reducing the number of multiply-add operations.
Experimental Results: High Accuracy, Low Energy
Experimental and simulation results show that the p-GAF-BP algorithm achieves a significant reduction in computation and energy consumption while maintaining comparable model accuracy. In the XOR logic gate task, the algorithm successfully completes network training through hardware experiments; in the MNIST handwritten digit recognition task, networks with 1 to 3 hidden layers all achieve more than 97% recognition accuracy, which is equivalent to the classic BP algorithm. More importantly, under the condition of achieving the comparable recognition accuracy, p-GAF-BP reduces the number of multiplication and addition operations in gradient calculation by about one order of magnitude and cuts energy consumption by about 79%. In the deeper ResNet18 network and CIFAR10 dataset, this method still maintains robust training ability, which fully proves its universality. It should be pointed out that this strategy of hardware acceleration for the derivative of activation functions through the sampling operation of SOT-MTJ true random number generator is not only applicable to sigmoid activation functions, but also can be extended to tanh functions and piecewise linear functions such as ReLU functions.
Innovation and Future Impact
This work integrates the physical characteristics of spintronic devices with the basic training algorithm of neural networks, creating a new paradigm of hardware-algorithm collaborative energy-saving AI training. Different from traditional network pruning, dropout and other methods, p-GAF-BP does not affect forward propagation or damage the network structure. It only dynamically screens effective gradients in the reverse stage through probabilistic sampling, and has good compatibility and scalability. In the future, with the integration and tapeout of spintronic devices, this method can be further applied to edge intelligent chips, low-power training equipment, and even extended to large-scale Transformer and large model training scenarios, providing support for green and inclusive AI. The above research results were published in the Newton journal under the title "Back Propagation Eased by Spintronic-Hardware-Sampled Probabilistic Gradient of Activation Function", with the DOI of https://doi.org/10.1016/j.newton.2026.100520, and relevant patents have been filed. XU Yingqian, a doctoral student from Group M02 of the Institute of Physics, Chinese Academy of Sciences (IOPCAS), is the first author, and Prof. HAN Xiufeng and Associate Prof. WAN Caihua from IOPCAS are the co-corresponding authors. This research was supported by the National Key Research and Development Program (MOST), the National Natural Science Foundation of China (NSFC) and the Chinese Academy of Sciences President's International Fellowship Initiative (PIFI).
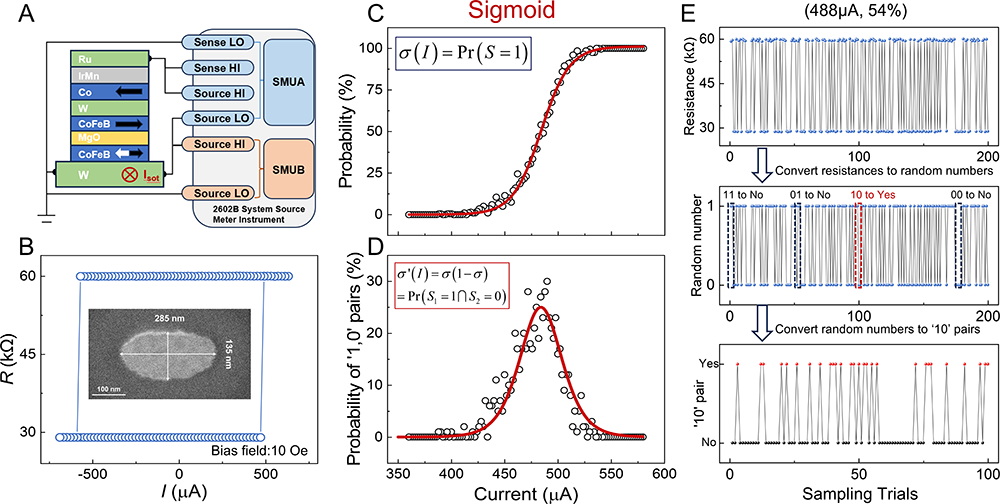
Figure 1: Schematic of activation function differentiation realized by SOT-MTJ. (A) Schematic of the test circuit. (B) Magnetization switching induced by current pulses; the inset shows a cross-sectional image of the SOT-MTJ. (C) The probability of sampling the high-resistance state as a function of the write current, which follows the Sigmoid curve. (D) The probability of sampling "1, 0" pairs as a function of the write current, which matches the derivative of the Sigmoid function. (E) Detailed procedure for obtaining "1, 0" pairs. (Image by Institute of Physics)
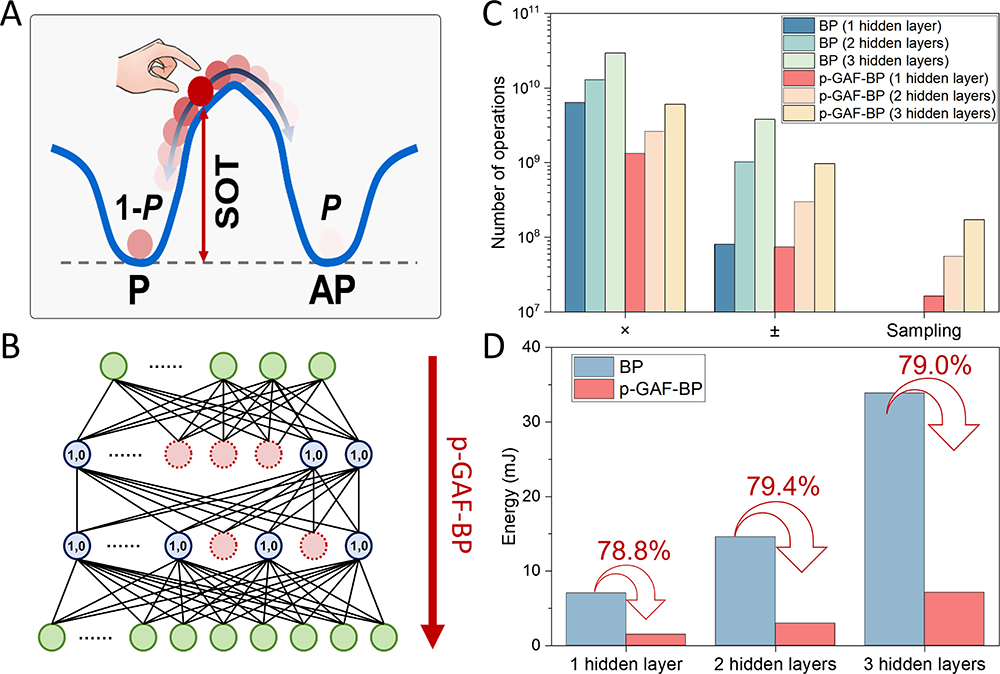
Figure 2: Activation function probabilistic gradient backpropagation algorithm based on spintronic hardware sampling. (A) Probabilistic switching characteristics of a high-barrier spin-orbit torque magnetic tunnel junction (SOT-MTJ). (B) In the probabilistic gradient activation function backpropagation (p-GAF-BP) algorithm, error backpropagation proceeds only through nodes with a sampling result of (1,0). (C–D) Comparison of the number of operations (C) and corresponding energy consumption (D) required for backpropagation gradient computation between BP and p-GAF-BP when the recognition accuracy on the MNIST dataset reaches 90%. (Image by Institute of Physics)
Contact:
HAN Xiufeng
Institute of Physics
Email:xfhan@iphy.ac.cn
Key words:
Spintronics; Magnetic tunnel junction; Back propagation;
Abstract:
Researchers developed a spintronic-hardware-sampled probabilistic gradient of activation function approach for neural-network training. By using the stochastic switching behavior of spin-orbit torque magnetic tunnel junctions, the method transforms deterministic gradient calculations into stochastic sampling processes, reducing multiplication operations and energy consumption during backpropagation.